Gravitational wave signal extraction against non-stationary instrumental noises with deep neural network
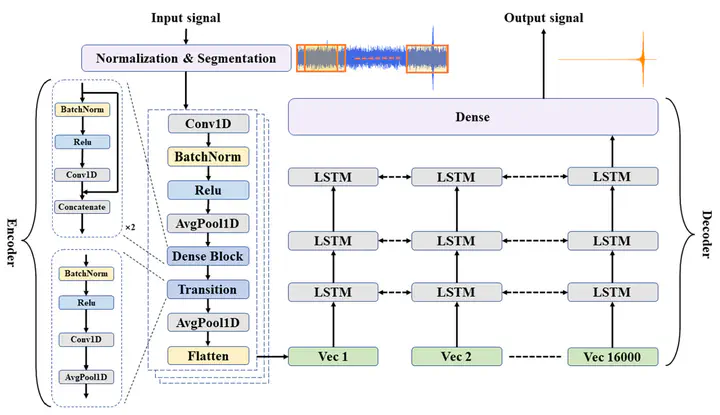 The architecture of our denoising autoencoder is delineated as follows. The input data is first subjected to normalization and segmentation (top left), resulting in the formation of overlapping subsequences. Each subsequence is then processed through the encoder to extract its characteristic feature vector. This is followed by passage through three bidirectional LSTM layers to yield predictive values. The final reconstructed waveform is then attained in the Dense layer (top right).
The architecture of our denoising autoencoder is delineated as follows. The input data is first subjected to normalization and segmentation (top left), resulting in the formation of overlapping subsequences. Each subsequence is then processed through the encoder to extract its characteristic feature vector. This is followed by passage through three bidirectional LSTM layers to yield predictive values. The final reconstructed waveform is then attained in the Dense layer (top right).Highlights
Robust Non-Stationary Denoising: First deep learning model specifically designed to handle three major types of non-stationarities in space-based gravitational wave data: data gaps, glitches, and time-varying noise.
Realistic Mission Scenarios: Addresses practical challenges from routine maintenance and unexpected disturbances that will occur during LISA/Taiji/TianQin science operations.
Maintained Performance: Achieves state-of-the-art accuracy for ideal data while demonstrating remarkable adaptability to anomalous conditions.
Comprehensive Anomaly Coverage: Successfully extracts massive black hole binary signals under individual non-stationarities and their complex mixtures.
Denoising Autoencoder Architecture: Novel bidirectional LSTM-based architecture specifically designed for gravitational wave signal extraction.
Mission-Critical Capability: Provides essential robustness for space-based detectors where non-stationary features are unavoidable.
Key Contributions
1. Addressing Real-World Data Challenges
Space-Based Detector Non-Stationarities
Unlike ground-based detectors, space-based missions face unique challenges:
- Extended Mission Duration: Multi-year operations (LISA: 4+ years) increase probability of anomalies
- Maintenance Requirements: Planned spacecraft operations causing data interruptions
- Environmental Variations: Solar activity, thermal variations, equipment aging
- Remote Operations: Limited intervention capabilities after launch
Three Critical Non-Stationarity Types
Data Gaps
- Routine maintenance windows
- Communication blackouts
- Instrument calibration periods
- Unexpected data loss
Transients (Glitches)
- Instrumental artifacts
- Environmental disturbances
- Micro-meteoroid impacts
- Spacecraft maneuvers
Time-Varying Noise Autocorrelations
- Thermal fluctuations
- Equipment degradation
- Solar activity variations
- Orbital position effects
2. Deep Learning Architecture
Denoising Autoencoder Design
The model architecture consists of:
Encoder
- Input: Normalized and segmented gravitational wave data with noise
- Overlapping subsequences for temporal coherence
- Feature extraction layers capturing multi-scale patterns
- Compression to characteristic feature vectors
Bidirectional LSTM Processing
- Three stacked bidirectional LSTM layers
- Forward and backward temporal context integration
- Captures long-range dependencies in signal structure
- Handles sequential patterns across extended durations
Decoder
- Dense layers for reconstruction
- Gradient-based refinement of waveform estimates
- Output: Cleaned gravitational wave signal
- Preserves phase and amplitude accuracy
Architecture Advantages
- Bidirectional processing critical for handling gaps (uses future context)
- LSTM memory cells maintain coherence across non-stationary regions
- Autoencoder framework learns robust signal representation
- End-to-end training for optimal denoising
3. Comprehensive Robustness Validation
Systematic Testing Protocol
- Individual non-stationarity types tested separately
- Pairwise combinations evaluated
- Triple combination (all three types simultaneously)
- Various severity levels and configurations
Performance Metrics
- Signal recovery accuracy (waveform fidelity)
- Phase preservation (critical for parameter estimation)
- Amplitude estimation errors
- Comparison with ideal-case performance
Methodology
Data Generation
Gravitational Wave Signals
- Massive black hole binary coalescences
- Mass range: 10⁴ to 10⁷ solar masses
- Inspiral-merger-ringdown phenomenological waveforms
- Various mass ratios, spins, sky locations, distances
- Time-domain waveforms in detector frame
Noise Modeling
Baseline Noise
- Instrumental noise from LISA/Taiji sensitivity curves
- Galactic confusion noise from unresolved binaries
- Power spectral density-based generation
- Realistic amplitude and frequency characteristics
Non-Stationary Components
- Data gaps: Random duration and placement
- Glitches: Various morphologies (sine-Gaussians, wavelets)
- Time-varying noise: Modulated autocorrelation function
- Multiple simultaneous non-stationarities
Training Procedure
Dataset Construction
- Training set: Signals with various non-stationarity combinations
- Validation set: Independent parameter draws with anomalies
- Test set: Held-out parameters and anomaly configurations
- Data augmentation: Random time shifts, amplitude variations
Normalization and Segmentation
- Z-score normalization per data segment
- Overlapping windowing for temporal smoothness
- Segment length chosen for computational efficiency and context
- Padding strategies for edge effects
Training Strategy
- Loss function: Mean squared error between clean signal and reconstruction
- Optimizer: Adam with learning rate scheduling
- Early stopping on validation loss
- Batch training for efficiency
Robustness-Focused Training
- Explicit inclusion of non-stationary data in training
- Curriculum learning: gradually increasing anomaly severity
- Regularization to prevent overfitting to specific anomaly types
- Ensemble considerations for production deployment
Inference and Testing
Signal Extraction Pipeline
- Input: Raw detector data with unknown anomalies
- Normalization and segmentation
- Forward pass through encoder
- Bidirectional LSTM processing
- Decoder reconstruction
- Inverse normalization
- Output: Cleaned signal estimate
Evaluation Metrics
- Waveform overlap (match filter between true and recovered)
- Phase error (critical for parameter estimation)
- Amplitude recovery accuracy
- SNR improvement ratio
- Comparison benchmarks: ideal-case models, traditional methods
Results
Performance Under Ideal Conditions
Baseline Validation
- Match with state-of-the-art denoising models
- High fidelity signal reconstruction (overlap >95%)
- Phase errors <0.1 radians
- Amplitude recovery within 5%
- Confirms architecture effectiveness without anomalies
Data Gap Handling
Single Gap Scenarios
- Successfully bridges data gaps up to multiple hours
- Reconstruction using bilateral context
- Minimal degradation in gap regions
- Smooth transitions at gap boundaries
Multiple Gaps
- Maintains performance with multiple interruptions
- Cumulative gap duration up to significant fraction of observation
- Coherent signal reconstruction across fragmented data
Glitch Mitigation
Transient Artifact Removal
- Effective suppression of various glitch morphologies
- Preserves underlying gravitational wave signal
- Minimal residual artifacts
- Works for overlapping signal and glitch
Glitch Characteristics Tested
- Short-duration transients (milliseconds to seconds)
- Various amplitudes relative to signal
- Different frequency content
- Multiple glitches per observation
Time-Varying Noise Adaptation
Varying Autocorrelation
- Adapts to changing noise properties
- Maintains signal recovery despite non-stationarity
- No retraining required for different noise realizations
Comparison to Stationary Assumptions
- Traditional methods assuming stationary noise degrade
- Deep learning maintains robust performance
- Adaptive feature extraction critical
Combined Non-Stationarity Performance
Multiple Simultaneous Anomalies
- Tested with gaps + glitches + varying noise
- Remarkable adaptability to complex scenarios
- Performance degradation minimal compared to ideal case
- Critical validation for realistic mission conditions
Statistical Performance
- Consistent results across parameter space
- No catastrophic failures identified
- Graceful degradation with increasing anomaly severity
- Reliable for operational use
Signal-to-Noise Ratio Dependence
High SNR (>30)
- Excellent recovery even with severe non-stationarities
- Phase and amplitude highly accurate
Moderate SNR (10-30)
- Robust performance maintained
- Slight increase in errors but remains unbiased
- Practical operating regime for LISA/Taiji
Low SNR (<10)
- Challenging but functional
- Higher uncertainty but no systematic biases
- Suitable for detection followed by refined analysis
Impact
For Space-Based Gravitational Wave Missions
Operational Reliability
- Ensures science operations can continue despite anomalies
- Reduces data loss from non-stationary periods
- Enables use of full mission dataset
- Critical for maximizing return on investment
Mission Planning
- Informs maintenance scheduling strategies
- Provides confidence for handling unexpected events
- Supports risk assessment for operations
- Enables more aggressive science timelines
Data Quality Assurance
- Automated quality control through robust denoising
- Reduces need for manual intervention
- Consistent processing across mission duration
- Facilitates reproducible science results
For Deep Learning in Gravitational Wave Astronomy
Robustness Validation
- First comprehensive study of neural network robustness to realistic anomalies
- Demonstrates practical viability beyond controlled conditions
- Establishes testing protocols for future models
- Builds confidence for operational deployment
Architecture Insights
- Bidirectional LSTM effectiveness for handling gaps
- Autoencoder framework for signal preservation
- Feature learning robust to various disturbances
- Design principles applicable to other missions/sources
Methodology Development
- Training strategies for robustness
- Evaluation metrics for anomalous data
- Benchmark datasets for comparison
- Best practices for deployment
For Massive Black Hole Binary Science
Enhanced Detection Confidence
- Reliable signal extraction despite non-ideal data
- Reduced false positives from artifact confusion
- Improved parameter estimation accuracy
- Enables low-latency alerts for multi-messenger follow-up
Population Studies
- Full mission dataset usable for statistics
- Unbiased sample for astrophysical inference
- Maximum event discovery potential
- Support for cosmological applications
Resources
Publication
- Journal: Physics Letters B (2024)
- DOI: 10.1016/j.physletb.2024.139016
- arXiv: arXiv:2409.07957 [astro-ph, physics:physics]
Authors
- Yuxiang Xu
- Minghui Du
- Peng Xu
- Bo Liang
- He Wang
Background on Space-Based Detectors
LISA (Laser Interferometer Space Antenna)
- ESA/NASA collaboration
- Three spacecraft in heliocentric orbit
- Arm length: 2.5 million km
- Frequency band: 0.1 mHz - 1 Hz
Taiji
- Chinese mission concept
- Similar configuration to LISA
- Complementary sensitivity
- Timeline: 2030s
TianQin
- Chinese mission
- Geocentric orbit configuration
- Higher frequency focus
- Verification binaries
Non-Stationarity in Space Missions
Causes of Data Gaps
- Planned communication downlinks
- Spacecraft repointing maneuvers
- Calibration activities
- Solar conjunction periods
Sources of Glitches
- Micrometeoroid impacts
- Outgassing events
- Thermal transients
- Electronic anomalies
Time-Varying Noise Sources
- Solar wind variations
- Thermal environment changes
- Component aging
- Orbital phase dependencies
Related Deep Learning Work
Denoising Methods
- WaveFormer: Transformer-based approach
- Various autoencoder architectures
- Generative adversarial networks
- Diffusion models for signal processing
Robustness Studies
- Adversarial examples in physics
- Transfer learning across conditions
- Domain adaptation techniques
- Uncertainty quantification
Software and Tools
Deep Learning Frameworks
- PyTorch/TensorFlow implementations
- LSTM and recurrent architectures
- Time-series processing libraries
Gravitational Wave Tools
- LISA analysis software
- Waveform generation tools
- Noise simulation packages
- Data handling utilities
Future Directions
Methodological Extensions
- Attention mechanisms for improved gap handling
- Uncertainty estimation for reconstruction confidence
- Active learning for identifying challenging cases
- Transfer learning across missions
Additional Anomaly Types
- Laser frequency variations
- Pointing jitter
- Temperature excursions
- Novel instrumental artifacts
Multi-Source Scenarios
- Denoising with overlapping signals
- Confusion noise mitigation
- Global fit support
- Population-level robustness
Operational Integration
- Real-time processing pipelines
- Automated anomaly detection
- Quality flagging systems
- Mission operations support
Extended Applications
- Extreme mass ratio inspirals
- Galactic binary extraction
- Stochastic background analysis
- Other source types and missions