Lecture 1. Computer vision overview & Historical context
Table of Contents
CS231n 课程的官方地址:http://cs231n.stanford.edu/index.html
该笔记根据的视频课程版本是 Spring 2017(BiliBili),PPt 资源版本是 Spring 2018.
首先,我们针对 CS231n 这个课程,我们先回答下面一个问题:
1.1 What is Computer Vision?
有这样的一个事实:到2017年,互联网上大约80%的流量都是视频(CISCO)。 可见利用算法或模型去开发和理解这些视觉数据是很有必要的。然而,视觉数据存在着问题,那就是其很不容易被理解。讲师把视觉数据比作了物理学中的“暗物质”,是因为其占据了宇宙中的很大一部分,但是我们不能直接观测它们,去探知和理解它们。
又一个事实来自 YouTube:大概每秒钟就会有长达5小时的内容会被上传到 YouTube 上。显然,若给这些视频做标签,分类,发放广告等处理,YouTube 的员工人手不够的。
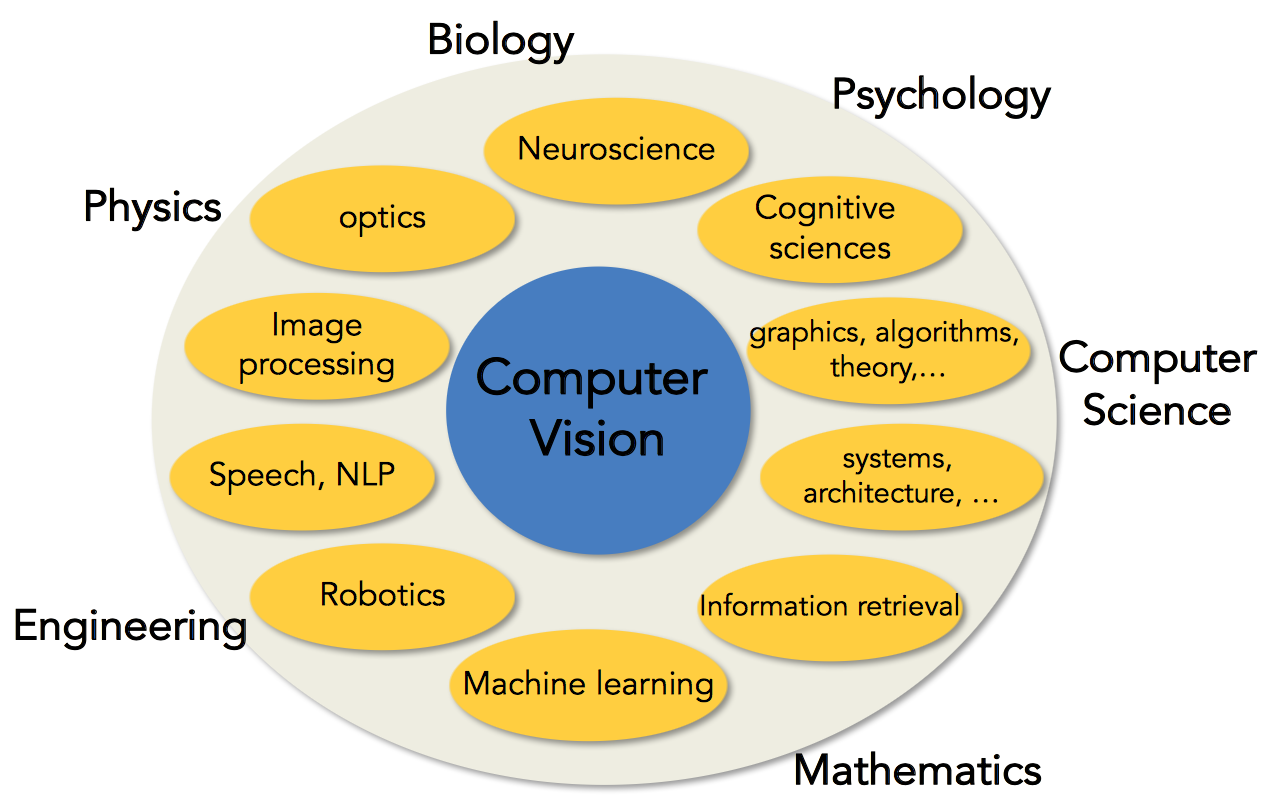
计算机视觉是一个跨学科的领域:
请自行从下图中体会一二。。。。
1.2 A brief history of computer vision
视觉的历史可以追溯到大约5亿4千3百万年前。简单说,那个时候的生物就一个字:low!连眼睛都没有!但是偏偏有那么短短的一千万年间(zoologists 说的,别找我。。。),物种指数级爆炸增长!为啥呢??一个帅哥给出了一个很有说服力的理论:因为有眼睛了啊!你说神奇不神奇!
现在,可以说有智慧的生物都是有视觉感知的(毫不谦虚的暗示了我们人类自己哈~)。人脑皮层里据说有一半的神经元都是和视觉有关呢!谁敢说视觉不重要啊?
扯完了生物的视觉,那机器的视觉算什么鬼呢?不好意思,我们继续飞到最原始的理解为好,来聊聊最早的"机器视觉"——相机。最早的相机乃是17世纪文艺复兴时期的一种暗箱(利用小孔成像原理)。其实这个原理和我们生物的眼睛没有本质的区别,当然也包括我们现代到处可见的手机摄像头等等。。。
生物学家最开始研究了生物视觉的原理,算是启发了计算机视觉的一项研究(Hubel&Wiesel, 1959),他们想知道哺乳动物的视觉处理机制是怎样的?于是,他们在猫脑子里管视觉的神经处查电极看反应。结果,视觉神经在不同层对不同的视觉影响有着不同的反应,其中复杂细胞对边界信息敏感。
计算机视觉的历史从60年代初开始。Block world 是其相关的第一篇工作,也是一篇 PhD 论文( Larry Roberts, 1963),其中视觉世界被简化为简单的几何形状,视觉以重建的方式识别。在1966年,一个现已非常著名且在当时颇有野心的 MIT 暑期项目——The Summer Vision Project 。50多年过去了,这个项目仍在持续的研究与视觉相关的根本性问题。David Marr 此人在70年代写了一本很有影响力的书《Vision》,书中都是他的对于视觉的个人理解以及对如何利用计算机开发和处理视觉的算法等等问题。这里视频里提到了一点细节,说白了就是想说理解视觉是一种”分层“、”分工“、”分步“的思维方式。70年代还有一个开创性的工作就是:我们如何越过简单的块状世界,开始识别或表示现实世界的对象?(Brooks&Binford, 1979; Fischler and Elschlager, 1973),其中的基本思想,说白了就是每个对象都是由简单的几何图像构成。80年代的 David Lowe 尝试了简单的线条重建视觉图像。总之,上述这些和现在相比,还是一个字:low!都还停留在 toy example 的阶段,没啥大的进展。
后来的发展,图像识别既然搞不成,那就从图像分割开始搞事情好了。于是,出现了 Normalized Cut(Shi&Malik, 1997)的图算法来像素级上进行分割。有一个应用的发展特别受到瞩目,那就是面部检测(Viola&Jones, 2001),在当时那股统计机器学习方法的浪潮下,这个用Adaboost算法实现的实时面部检测相当令人称赞。2000年以前10年里,重要思想是基于特征的目标识别,其中一个非常有影响力的工作是 ”SIFT“&Object Recognition(David Lowe, 1999)。这样相同构成要素特征去识别图片,使得我们可以在识别整幅图像有了进展,这里有个例子就是”空间金字塔匹配“(Spatial Pyramid Matching, Lazebnik, Schmid & Ponce, 2006),算法思想就不说了。。。类似的还有设计人体姿态(Histogram of Gradients,(HoG), Dalal&Triggs, 2005)和辨别人体姿态(Deformable Part Model, Felzenswalb, McAllester, Ramanan, 2009)。
进入21世纪以来,图片质量逐渐的越来越好。还有互联网的发展,相机硬件以及计算机视觉研究等等的进步。数据变得越来越多,越来越好,那么目标识别这个重要问题终于重回到人们的视野。于是,21世纪早期才开始有了真正有标签的数据集(PASCAL Visual Object Challenge),以供我们去对目标识别问题进行研究。这毕竟才20个类别的数据集。很快一个更加真实的数据集出现了(ImageNet),好家伙,有2.2万个标签,1400多万个图片!搞这么大的数据其实也和机器学习的问题有关,那就是数据量要是小了,会太容易过拟合的。为此花了3年搞出了这么个大数据集,从2009年开始组织了国际比赛,经过更严格筛选的测试集,1000种目标类别,140万个目标图像。于是,从2010年到2017年以来,每年的获胜队伍的算法错误率在不断的下降:
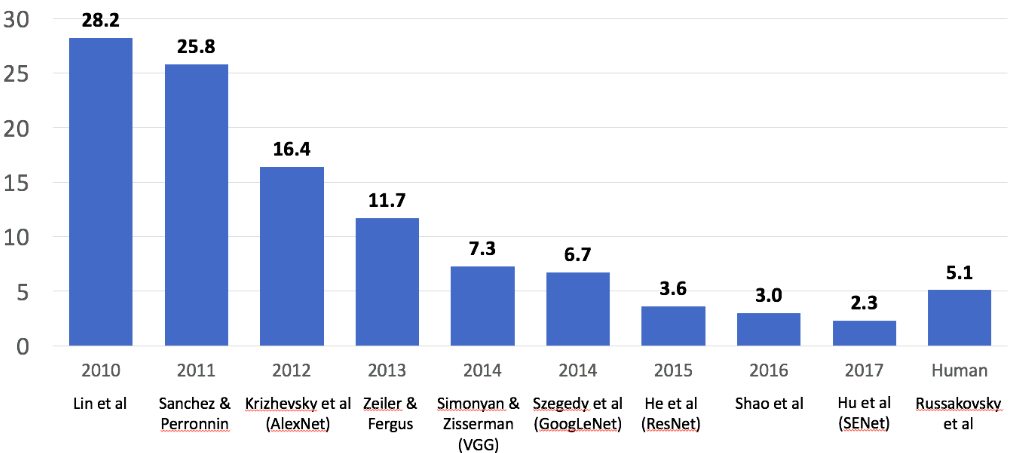
显然,很牛逼的一年是2012年!之前几年还徘徊在20%错误率,然而2012年一下子降了好多百分点,这就是卷积神经网络(CNN) 算法成名的一年啊!从此,神经网络以及深度学习等等概念都开始快速风靡起来。
1.3 CS231n Overview
首先要说的是,这门课程主要就是针对”图像分类“来搞事情的。不要小瞧这件事情看似很没意思,或者不够酷,其实所有的高深算法和让人惊讶的图像任务,都是基于,甚至源于”图像分类“技术的,比如说什么图像分割或者图像摘要生成等等。
CNN 卷积神经网络是我们主要讨论的东西,用来目标识别,有时也叫做 convnets。
自从2012年开始,ImageNet 的夺冠都是神经网络模型,并且深度越来越深。下图小窥一下:
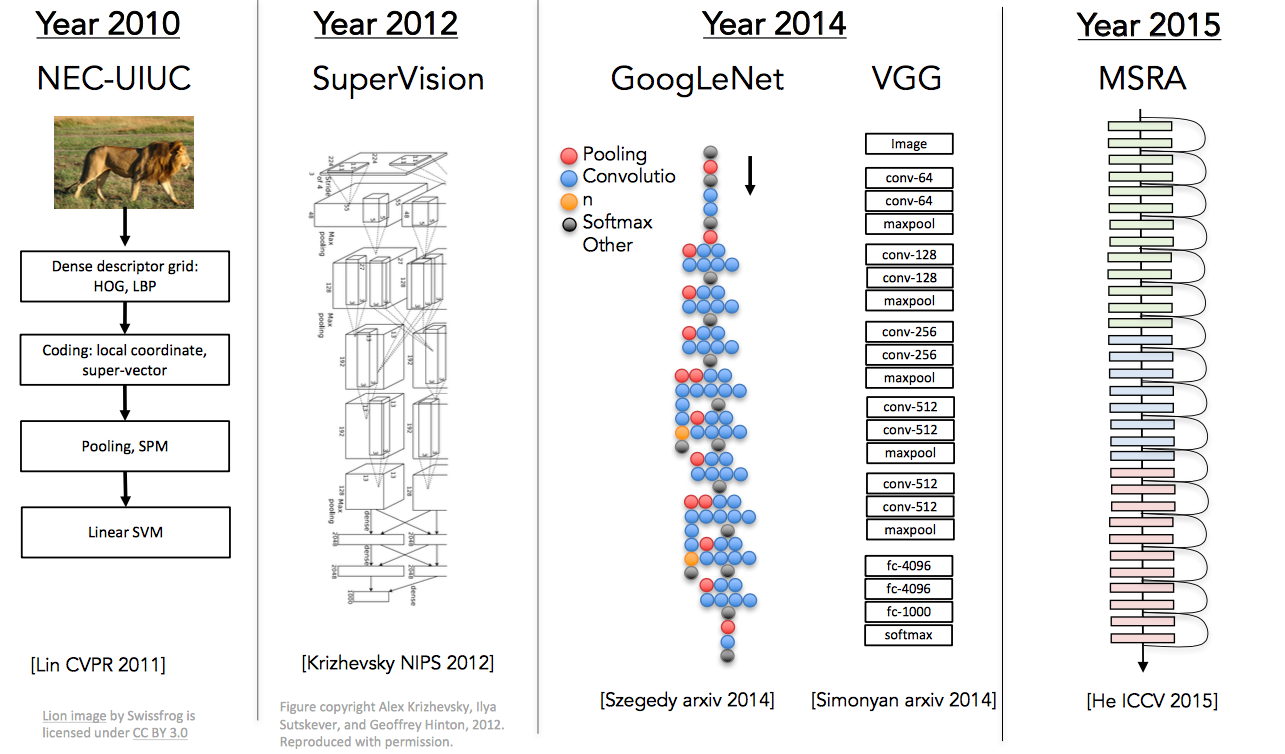
其实90年代时候,CNN 就已经被发明了,下图是当年的模型与2012年名声大噪的 AlexNet 的对比,在结构上也诸多的相似之处:
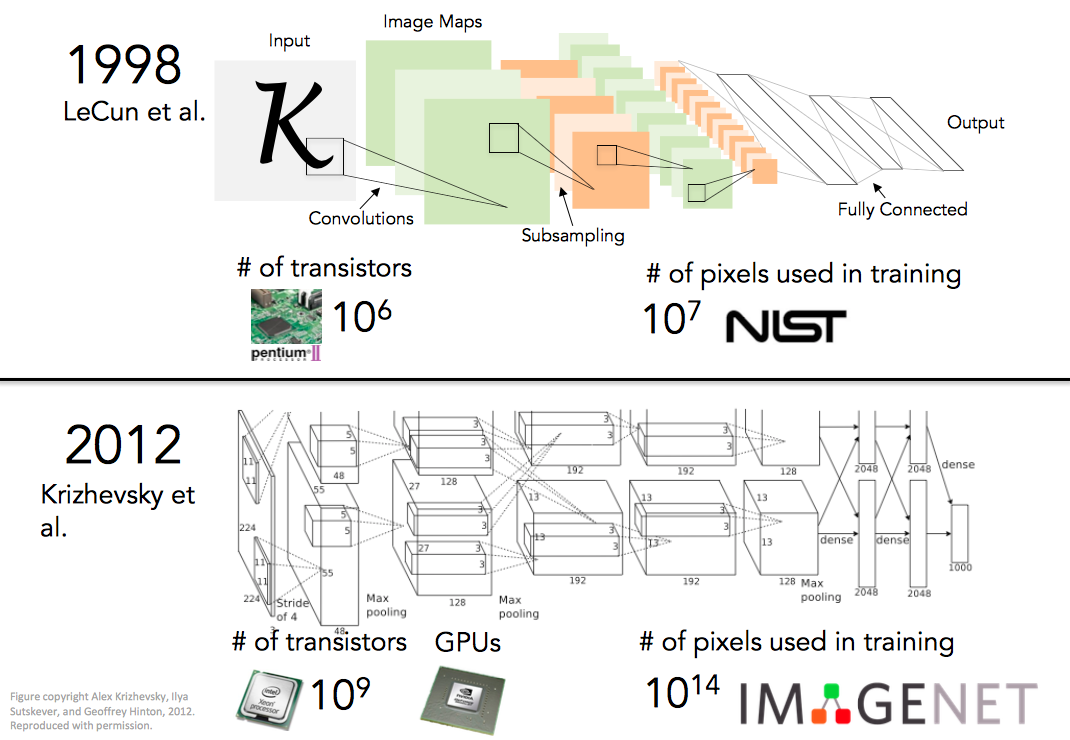
那么,你肯定狐疑了,为啥早就发明了,但是直到2012年才会突然大展拳脚,让大家满地找下巴呢?这是因为这些年以来以下深度学习三个方面的发展和进步导致的:
- 计算能力(computation)。根据摩尔定律,计算机的速度每年都在提高。何况我们还有 GPU 进行高效的并行运算。
- 数据(data)。这些算法需要庞大的数据才得以实现非常好的泛化效果,且避免了过拟合。
- 算法(algorithms)。正是深度神经网络的崛起,传统机器学习算法的落寞。
和人的视觉系统相比,我们的计算机视觉还有很大的潜力和进步空间。那么你晓得计算机视觉的圣杯是什么么?那就是仅仅根据一张图片,计算机就能写出一部小说来。。。。(个人认为这不仅仅是记忆力只是储存的问题,这是一个想象力的问题,不过记忆力的本质本来就是想象力,所以可能还是一个问题)。当然,对于一张图片的深刻理解也是很重要的,诸如暗喻,讽刺,幽默等等。
- 花书是课程推荐选读用书。
References
Hubel, David H., and Torsten N. Wiesel. “Receptive fields, binocular interaction and functionalarchitecture in the cat’s visual cortex.” The Journal of physiology 160.1 (1962): 106. [PDF]
Roberts, Lawrence Gilman. “Machine Perception of Three-dimensional Solids.” Diss. MassachusettsInstitute of Technology, 1963. [PDF]
Marr, David. “Vision.” The MIT Press, 1982. [PDF]
Brooks, Rodney A., and Creiner, Russell and Binford, Thomas O. “The ACRONYM model-based vision system. " In Proceedings of the 6th International Joint Conference on Artificial Intelligence (1979): 105-113. [PDF]
Fischler, Martin A., and Robert A. Elschlager. “The representation and matching of pictorial structures.” IEEE Transactions on Computers 22.1 (1973): 67-92. [PDF]
Lowe, David G., “Three-dimensional object recognition from single two-dimensional images,” Artificial
Intelligence, 31, 3 (1987), pp. 355-395. [PDF]
Shi, Jianbo, and Jitendra Malik. “Normalized cuts and image segmentation.” Pattern Analysis and
Machine Intelligence, IEEE Transactions on 22.8 (2000): 888-905. [PDF]
Viola, Paul, and Michael Jones. “Rapid object detection using a boosted cascade of simple features.” Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on. Vol. 1. IEEE, 2001. [PDF]
Lowe, David G. “Distinctive image features from scale-invariant keypoints.” International Journal of
Computer Vision 60.2 (2004): 91-110. [PDF]
Lazebnik, Svetlana, Cordelia Schmid, and Jean Ponce. “Beyond bags of features: Spatial pyramid
matching for recognizing natural scene categories.” Computer Vision and Pattern Recognition, 2006IEEE Computer Society Conference on. Vol. 2. IEEE, 2006. [PDF]
Dalal, Navneet, and Bill Triggs. “Histograms of oriented gradients for human detection.” ComputerVision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on. Vol. 1. IEEE,2005. [PDF]
Felzenszwalb, Pedro, David McAllester, and Deva Ramanan. “A discriminatively trained, multiscale,deformable part model.” Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEEConference on. IEEE, 2008 [PDF]
Everingham, Mark, et al. “The pascal visual object classes (VOC) challenge.” International Journal ofComputer Vision 88.2 (2010): 303-338. [PDF]
Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” Computer Vision and PatternRecognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009. [PDF]
Russakovsky, Olga, et al. “Imagenet Large Scale Visual Recognition Challenge.” arXiv:1409.0575. [PDF]
Lin, Yuanqing, et al. “Large-scale image classification: fast feature extraction and SVM training.”
Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on. IEEE, 2011. [PDF]
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep
convolutional neural networks.” Advances in neural information processing systems. 2012. [PDF]
Szegedy, Christian, et al. “Going deeper with convolutions.” arXiv preprint arXiv:1409.4842 (2014).
[PDF]
Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale imagerecognition.” arXiv preprint arXiv:1409.1556 (2014). [PDF]
He, Kaiming, et al. “Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.“arXiv preprint arXiv:1406.4729 (2014). [PDF]
LeCun, Yann, et al. “Gradient-based learning applied to document recognition.” Proceedings of theIEEE 86.11 (1998): 2278-2324. [PDF]
Fei-Fei, Li, et al. “What do we perceive in a glance of a real-world scene?.” Journal of vision 7.1 (2007):10. [PDF]