贝叶斯深度学习前沿进展 (朱军教授)
My lecture note on 「Bayesian Deep Learning」
此文是关于"第十八届中国机器学习及其应用研讨会“上,朱军教授的「讲座笔记」。内容仅涉及我个人感兴趣的要点内容。
Table of Contents
这是一个信息量很大的报告。
关于深度贝叶斯研究的动机
- 源自对数据或环境不确定性的建模和推断,甚至有时是对抗性的!
- 源自模型的不确定性。模型有庞大的参数数目,而数据还存在着大量的冗余。所以,用大模型在有限的数据上训练,就会带来不确定性。再者,单个模型的输出也完全没法表征结果的不确定性。
关于贝叶斯机器学习
Bayesian (Probabilistic) Machine Learning 的两篇 outlook/review 文章推荐:
Modeling: Deep Resolution of Bayesian ML
- How to do Bayesian inference for DNNs?
- How to learn hierarchically structured Bayesian models?
大体上,可以分为两类做法:
Type-1: Bayes -> DNN
用贝叶斯推断的办法来做神经网络。网络有多大,贝叶斯推断做在上面也会有同样的规模。
Marriage between Bayesian Methods and Neural Networks
早期的尝试,网络都很浅层。有两个人物值得留意:David MacKay 及其导师 John J. Hopfield,在 David 的博士论文曾讨论一个问题:是否可以用贝叶斯推断帮助我们保护神经网络避免过拟合,帮我们来选择合适的网络。
结论是很简单和直接的:
Bayes embodies Occam’s Razor and Apply to Bayesian neural netoworks.
几乎在同时,G. Hinton 的博士生 R.M. Neal 曾也谈到:如何用贝叶斯学习来做神经网络。
Bayesian Neural Networks (BNNs)
Neal 还得出一个后来被广泛应用且很漂亮的结论:
Two-layer Bayesian nerual networks, zero-mean Gaussian prior. Converge to Gaussian Processes (GPs) when the number of hidden units gets infinity. Generally, Bayesian nerual networks improve generalization, avoid overfitting!
即使只包含一个隐藏层的神经网络,在一定的先验假设下,让隐藏层无穷宽事实上等价于收敛到一个高斯过程。一般结论是:对一个神经网络做一个贝叶斯推断的话,一般就会提高泛化性和避免过拟合。[Neal, PhD thesis, 1995] [MacKey, Gaussian Process: a Replacement for Supervised Neural Networks, 1997].
高斯过程是一个经典的随机过程。高斯过程和 kernel function 有着千丝万缕的关系。
Dropout as an Approximate Bayesian Inference

谈到 Droput 作为近似贝叶斯推断的一种方法,那就不得不提下面两篇文章了:
新的研究工作企图理解 Dropout 的工作原理,Dropout 实际上等价于是在做一种深度的高斯过程的贝叶斯变分近似推断,我们还可以估计其中的不确定性,衡量其中的不确定度,即 MC-Dropout,实际上是基于后验采样的方法估计的。
Bayesian Methods of for Infering Architectures
神经网络结构的搜索。论神经网络的结构能否用一个随机过程刻画呢?
(上面👆可能给的文献不对~)
新的进展下可以感受到,网络结构所刻画的不确定性某种意义上比参数所刻画的不确定性是更高效的,更符合真实情况的。
除了用贝叶斯方法来做神经网络,目标把神经网络做的越来越好,另外一个方向,就是改变贝叶斯模型,用神经网络来实现它。
Type-2: DNN -> Bayes
Deep Bayesian Learning
Use DNNs to fit (learn) the complex relationships between random variables
Two types: Explicit models (e.g.: VAE, Flow-based Models), Implicit models (e.g.: GAN)
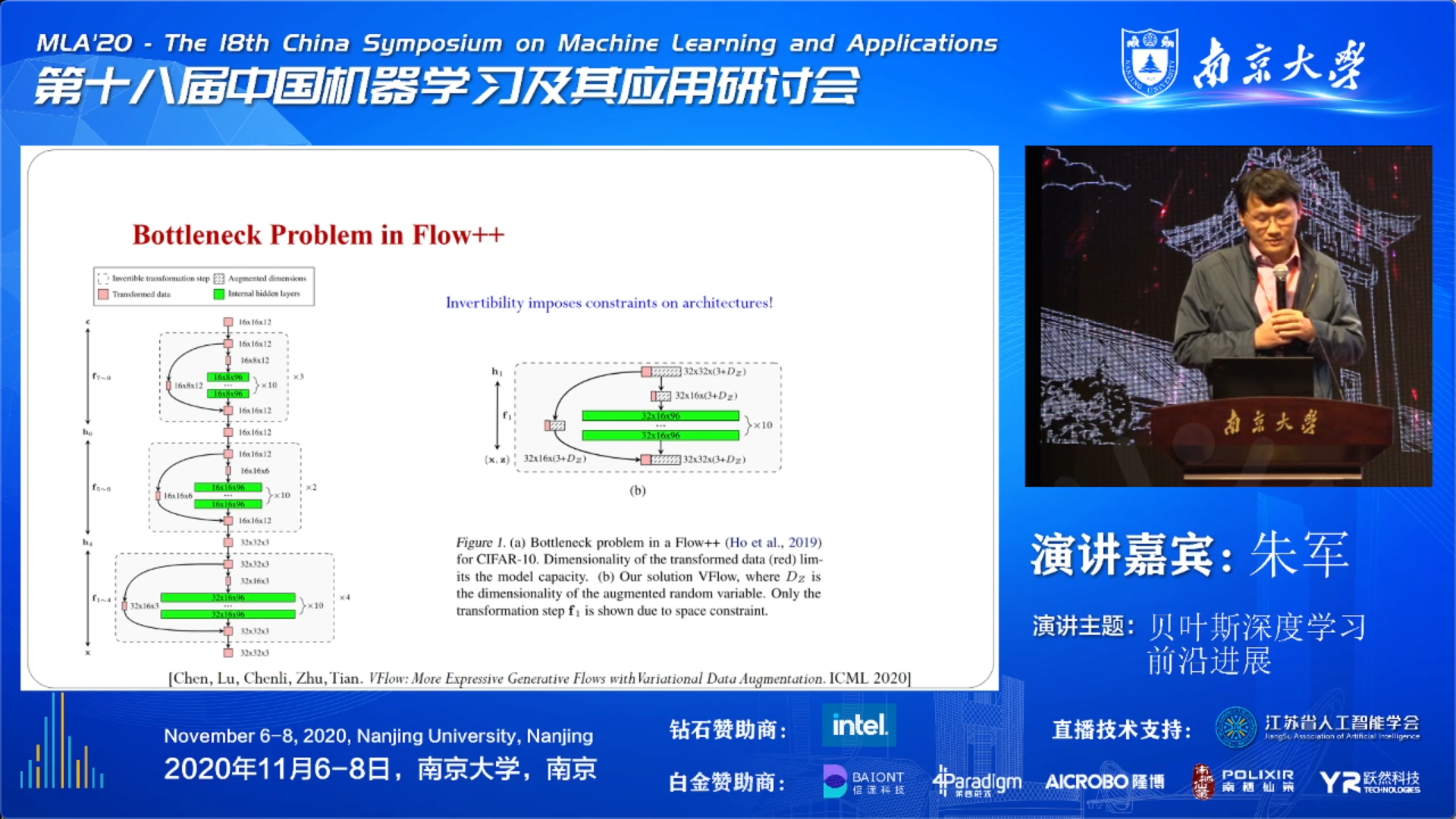
Flow-based Models
下面不妨特意谈谈其中的 Flow 模型。


然后介绍了一个目前 state of the art 的 Flow++ 模型,不过其也带来了 Bottleneck 问题。因此,朱老师谈到他们今年的一个工作来解决这个问题。

Algorithms
- How to compute posteriors efficiently?
- How to learn parameters?
总体来说,有两类方法:变分方法和蒙特卡洛方法。它们各自有优缺点。
提及到的文献:

朱老师在这里提到了哈密顿蒙特卡洛方法,可以处理高维空间中后验采样的问题。它实际上是用了一个动力学系统并利用梯度信息来引导粒子的演化方向,来达到快速收敛。在理论上,不计代价的话这确实是准确的,可以收敛到最优解。但是这个方法在高维空间效率是很低的,迭代次数太多,粒子的利用效率也不高,多个粒子可能会塌缩在一起的情况。
下面讲两个例子,分别引出朱老师自己的工作:
VAE 和 VAE 所面临的问题:
Inference path 中的 q 如果定义的不合适,那么优化算法即使再好,也只能得到一个近似解,无法消除误差。


朱老师他们考虑能不能把 q 这个变分分布的假设去掉。原先是用一个参数模型来定义,那么现在隐式的表示函数形式会如何呢。这个问题虽然好提,但不好解决。首先是需要基于变分分布 q 算期望很困难,隐式的函数是不清楚其形式的。另外还需要算它的梯度也是很困难,在朱老师这里是一个 $\log q$ 来表示的,不知道长什么样的就没法求梯度。
因此就变成一个函数估计问题:能否从未知 q 分布的样本中估计出 $\log q$ 的一个梯度。即通过数据估计函数。

朱老师考虑从函数空间里来思考这个问题,想能否通过函数空间中这些样本点来把梯度构造出来。这里的小技巧类似于 PCA 和 SVD 那样做分解,是要在函数空间上做 spectral 分解,由此可以得到一个精确的表示,即上面 👆 slide 中第一个公式。公式中的正交基函数可以通过一个核函数的谱分解来实现,即上面👆 slide 中的第二个公式。

为了可以实现计算,朱老师他们用到了 Nystrom 方法,从而得到了一个实际可以计算的估计器。

进一步分析与真实梯度之间的关系。其 error 的上界可以分析出来,采样数目 M 足够多的话,红色公式部分是接近于 0。J 是做 truncation 的 level,蓝色部分在 truncation 的 level 提升时,也会下降的。
这个梯度估计可以嵌入到任何一个基于梯度的方法中,无论是变分还是蒙特卡洛。从上面的定量分析效果也是还不错的。


今年,朱老师还更进一步做了一个工作。根据不同组所构造的梯度估计器,基于非参的 score estimators,做了一个统一的理论框架。发现大家做的不同的估计器,其实对应于不同的 kernel 的选择,及其对应的正则化项选择。基于这个分析,给出了统一的收敛性分析,改进了原先的分析结果,并且 recover 了 KEF 的结果,并且还给出理论保证。

随后,朱老师非常贴心的给了一屏幕的算法文献作为参考,暂时不在这里罗列了,有些工作太新还差不到收录(当然主要都是朱老师参与的工作)。
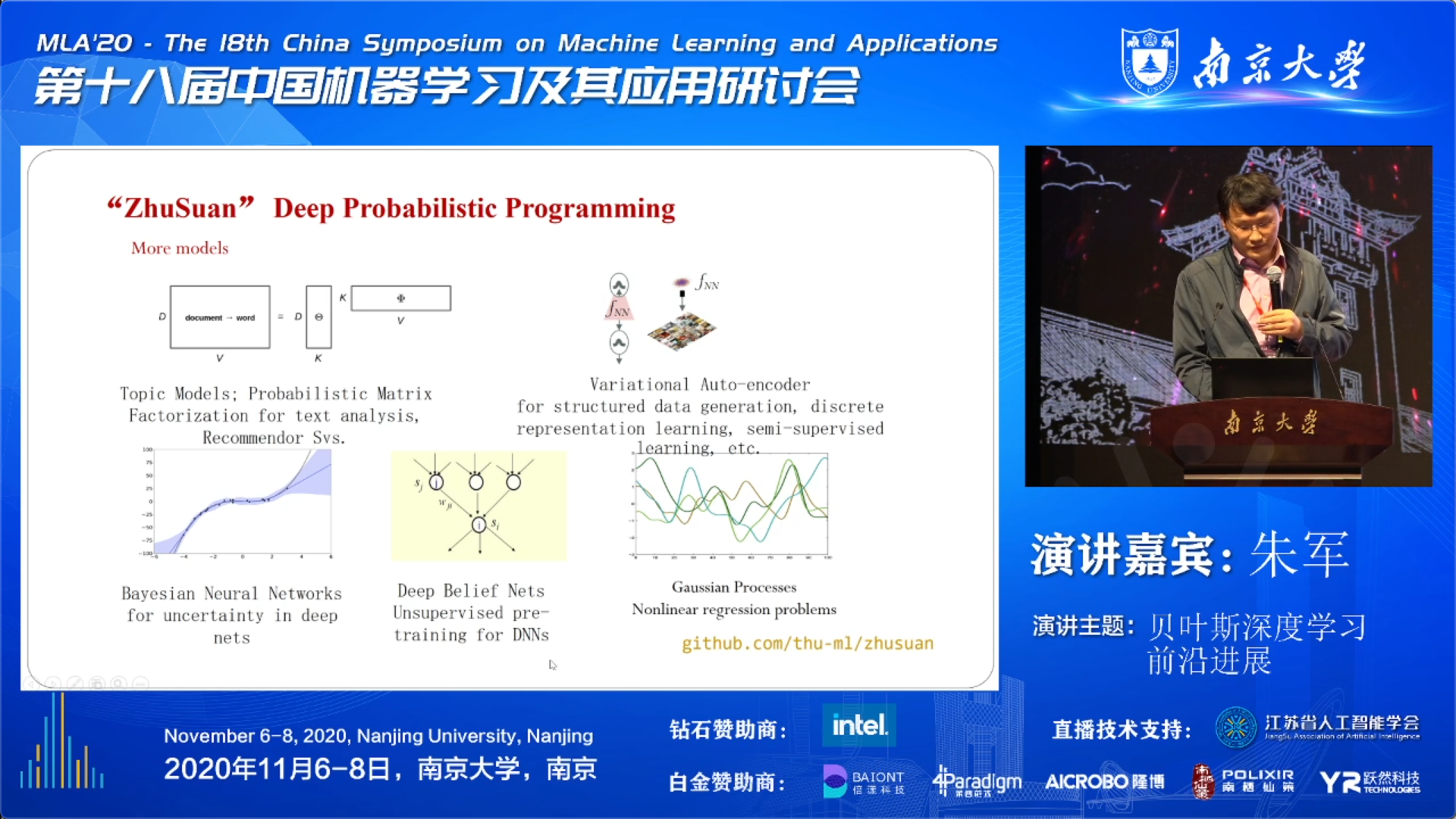
Probabilistic Programming Library (ZhuSuan)
- How to auto/semi-auto implement Bayesian deep learning models?
最后,朱老师谈了他们开发和维护的概率模型开源库:
- “ZhuSuan” Provides a User-Friendly Library for Deep Probabilistic Programming
- Github: https://github.com/thu-ml/zhusuan(TensorFlow 为主)
- Online Document: https://zhusuan.readthedocs.io
里面已经支持了领域内很多很好的算法:

还有一些常用的模型库:
Example
- What problems can be solved by Bayesian deep learning?
这部分就略过了,详细还是看 slides 吧。