为啥一定用残差图检查你的回归分析?
 Image credit: TagTeam
Image credit: TagTeam先说残差图究竟是什么鬼。
残差图是指以残差为纵坐标,以任何其他指定的量为横坐标的散点图。(上图仅是残差的示意图,非残差图,残差图可见下文)
用普通最小二乘法(OLS)做回归分析的人都知道,回归分析后的结果一定要用 残差图(residual plots) 来检查,以验证你的模型。你有没有想过这究竟是为什么?残差图又究竟是怎么看的呢?
这背后当然有数学上的原因,但是这里将着重于聊聊概念上的理解。从根本上说,随机性(randomness)和不可预测性(unpredictability)是任何回归模型的关键组成部分,如果你没有考虑到这两点,那么你的模型就不可信了,甚至说是无效的。
为什么这么说呢?首先,对于一个有效的回归模型来说,可以细分定义出两个基本组成部分:
Response =(Constant + Predictors)+ Error
我想说的是另一种说法,那就是:
响应(Response) = 确定性(Deterministic) + 随机性(Stochastic)
(有时候真是不得不吐槽下,毕竟是外国人发明的现代科学,中文翻译过来难眠有混淆视听之嫌,学术词汇的理解还是看英文更能清晰本质,一会就会聊到Stochastic就明白为什么这么说)
1. 确定性部分 (The Deterministic Portion)
为了完整,先提一下Deterministic这部分。在预测模型中,该部分是由关于预测自变量的函数组成,其中包含了回归模型中所有可解释、可预测的信息。
2. 随机误差 (The Stochastic Error)
Stochastic 这个词很牛逼,其不仅蕴含着随机性(random),还有不可预测性(unpredictable)。这是很重要的两点,往往很多朋友都以为有随机性的特点就够了,其实不然。这两点放在一起,就是在告诉我们回归模型下的预测值和观测值之间的差异必须是随机不可预测的。换句话说,在误差(error)中不应该含有任何可解释、可预测的信息。
模型中的确定性部分应该是可以很好的解释或预测任何现实世界中固有的随机响应。如果你在随机误差中发现有可解释的、可预测的信息,那就说明你的预测模型缺少了些可预测信息。那么残差图(residual plots)就可以帮助你检查是否如此了!
小注:回归残差其实是真实误差(ture error)的估计,就好比回归系数是真实母体系数(ture population coefficients)的估计。
3. 残差图 (Residual Plots)
我们可以用残差图来估计观察或预测到的误差error(残差residuals)与随机误差(stochastic error)是否一致。用一个丢骰子的例子最好理解了。当你丢出去一个六面的骰子时,你不应该能够预测得到哪面点数向上。然而,你却可以评估在一系列投掷后,正面向上的数字是否遵循一个随机模式,你自己心中就会想象出一个随机散布的残差图。如果,有人背着你对骰子做了点手脚,让六点更频繁的出现向上,这时你心中的残差图看上去就似乎有规律可循,从而不得不修改心中的模型,让你狐疑骰子一定有问题。
相同的原则也适用于回归模型。你不应该能够预测任何给定的观察或预测结果的错误(或者说差别)。你需要确定残差是否与随机误差相互呈现一致性,就像丢骰子一样,残差若整体呈现“很古怪”的模式,你就需要回头修改你的回归模型了。上面“古怪”究竟怎么看呢?看下文。
话说,OLS回归模型的随机误差到底是什么样子的呢?首先,残差不应该成片的很高或很低,而是在拟合值的范围内,残差应该以0为中心。换句话说,模型的拟合应该平均散布在被拟合值点附近。而且,在OLS理论中,假设随机误差产生的是正态分布的残差。因此,残差应该是以对称的模式,并且在整个拟合范围内具有恒定均匀的扩散,如下图python代码和绘图:
%matplotlib inline
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
# 给任务单独分配随机种子
np.random.seed(sum(map(ord
, "anscombe")))
import seaborn as sns
anscombe = sns.load_dataset("anscombe")
sns.residplot(x="x", y="y"
, data=anscombe.query("dataset == 'I'")
, scatter_kws={"s": 80})
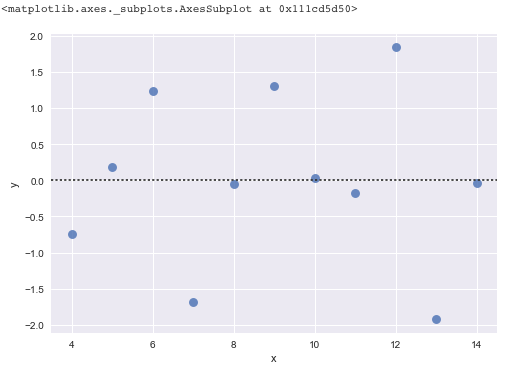
这是用Seaborn画的美图。拟合的好,就是0均值的白噪声分布$N(0,\sigma^2)$,不含任何人为模态。
下面来看一个有问题的残差图。请一定要记住,残差不应该包含任何可预测的信息。
sns.residplot(x="x", y="y"
, data=anscombe.query("dataset == 'II'")
, scatter_kws={"s": 80})
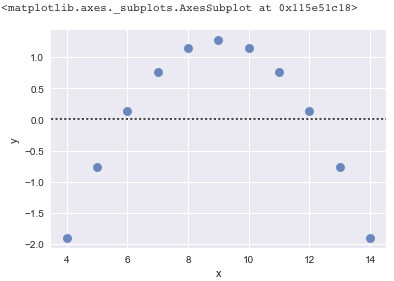
在上图中,你就可以根据拟合值来预测残差的非零值。例如,拟合值为9的预期残差为正值,而5和13的拟合值具有负的预期残差。
残差中的非随机模式表明模型的确定部分(预测变量)没有捕获一些“泄露”到残差中的一些可解释/可预测信息。该图表明模型几种没法解释的可能性,可能性包括:
- 一个缺失的变量
- 模型缺少一个变量的高阶项来解释曲率
- 模型缺少在已经存在的项之间的相互作用项(交叉项)
- 由此来回溯去修改模型,以期望修改后的残差图是理想中的残差图。
除了上述之外,还有两种预测信息会潜入到了残差中的方式:
- 残差不应该与另外的变量有所相关。如果你可以用另一个变量预测出此残差图,那么该变量就应该考虑到你的模型当中。那么就可以通过绘制其他变量的残差图,来考察这个问题。
- 相邻残差(Adjacent residuals)不应该相互关联(残差的自相关性)。如果你可以使用一个残差来预测得到下一个残差,则说明存在一些模型还未捕捉到的可预测信息。通常来说,这种情况涉及时间有序的观察预测。例子就不举了。
综上,若非要一句话小结,那就是要留意两个细节:正确的残差图不仅要体现出随机性(random),还要体现不可预测性(unpredictable)即可。
以上。
Ref: