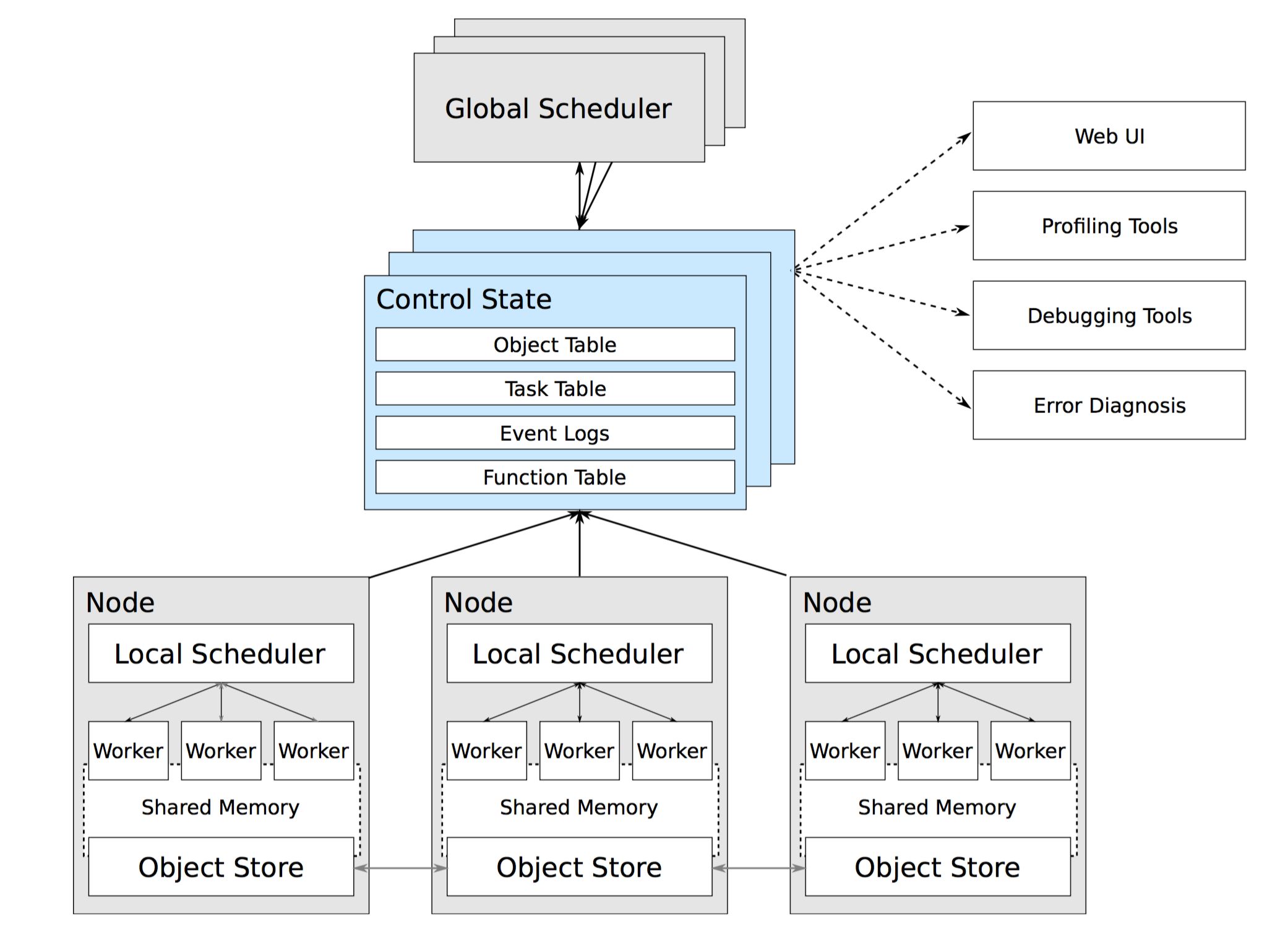
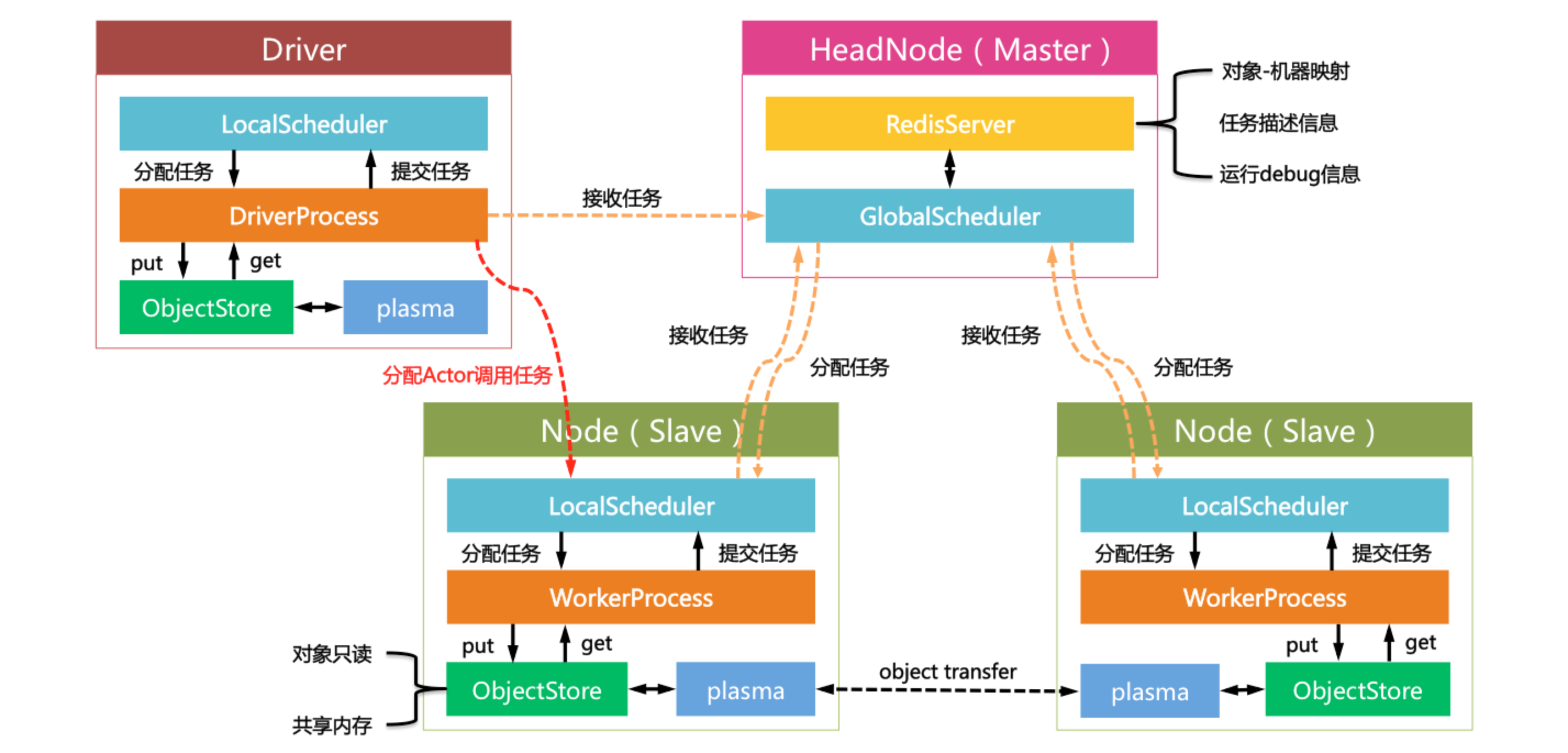
GOAL: The goal of this exercise is to show how to run simple tasks in parallel.
This script is too slow, and the computation is embarrassingly parallel. In this exercise, you will use Ray to execute the functions in parallel to speed it up.
Concept for this Exercise - Remote Functions
The standard way to turn a Python function into a remote function is to add the @ray.remote decorator. Here is an example.
# A regular Python function.defregular_function():return1# A Ray remote function.@ray.remotedefremote_function():return1
The differences are the following:
Invocation: The regular version is called with regular_function(), whereas the remote version is called with remote_function.remote().
Return values:regular_function immediately executes and returns 1, whereas remote_function immediately returns an object ID (a future) and then creates a task that will be executed on a worker process. The result can be obtained with ray.get.
Start Ray. By default, Ray does not schedule more tasks concurrently than there are CPUs. This example requires four tasks to run concurrently, so we tell Ray that there are four CPUs. Usually this is not done and Ray computes the number of CPUs using psutil.cpu_count(). The argument ignore_reinit_error=True just ignores errors if the cell is run multiple times.
The call to ray.init starts a number of processes.
EXERCISE: The function below is slow. Turn it into a remote function using the @ray.remote decorator.
# This function is a proxy for a more interesting and computationally# intensive function.@ray.remotedefslow_function(i):time.sleep(1)returni
EXERCISE: The loop below takes too long. The four function calls could be executed in parallel. Instead of four seconds, it should only take one second. Once slow_function has been made a remote function, execute these four tasks in parallel by calling slow_function.remote(). Then obtain the results by calling ray.get on a list of the resulting object IDs.
# Sleep a little to improve the accuracy of the timing measurements below.# We do this because workers may still be starting up in the background.time.sleep(2.0)start_time=time.time()results=ray.get([slow_function.remote(i)foriinrange(4)])end_time=time.time()duration=end_time-start_timeprint('The results are {}. This took {} seconds. Run the next cell to see ''if the exercise was done correctly.'.format(results,duration))# The results are [0, 1, 2, 3]. This took 1.0055913925170898 seconds. Run the next cell to see if the exercise was done correctly.
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertresults==[0,1,2,3],'Did you remember to call ray.get?'assertduration<1.1,('The loop took {} seconds. This is too slow.'.format(duration))assertduration>1,('The loop took {} seconds. This is too fast.'.format(duration))print('Success! The example took {} seconds.'.format(duration))# Success! The example took 1.0055913925170898 seconds.
EXERCISE: Use the UI to view the task timeline and to verify that the four tasks were executed in parallel. After running the cell below, you’ll need to click on View task timeline".
Using the second button, you can click and drag to move the timeline.
Using the third button, you can click and drag to zoom. You can also zoom by holding “alt” and scrolling.
NOTE: Normally our UI is used as a separate Jupyter notebook. However, for simplicity we embedded the relevant feature here in this notebook.
NOTE: The first time you click View task timeline it may take several minutes to start up. This will change.
NOTE: If you run more tasks and want to regenerate the UI, you need to move the slider bar a little bit and then click View task timeline again.
NOTE: The timeline visualization may only work in Chrome.
importray.experimental.uiasuiui.task_timeline()
Exercise 2 - Parallel Data Processing with Task Dependencies
GOAL: The goal of this exercise is to show how to pass object IDs into remote functions to encode dependencies between tasks.
In this exercise, we construct a sequence of tasks each of which depends on the previous mimicking a data parallel application. Within each sequence, tasks are executed serially, but multiple sequences can be executed in parallel.
In this exercise, you will use Ray to parallelize the computation below and speed it up.
Concept for this Exercise - Task Dependencies
Suppose we have two remote functions defined as follows.
@ray.remotedeff(x):returnx
Arguments can be passed into remote functions as usual.
Object IDs can also be passed into remote functions. When the function actually gets executed, the argument will be a retrieved as a regular Python object.
So when implementing a remote function, the function should expect a regular Python object regardless of whether the caller passes in a regular Python object or an object ID.
Task dependencies affect scheduling. In the example above, the task that creates y1_id depends on the task that creates x1_id. This has the following implications.
The second task will not be executed until the first task has finished executing.
If the two tasks are scheduled on different machines, the output of the first task (the value corresponding to x1_id) will be copied over the network to the machine where the second task is scheduled.
These are some helper functions that mimic an example pattern of a data parallel application.
EXERCISE: You will need to turn all of these functions into remote functions. When you turn these functions into remote function, you do not have to worry about whether the caller passes in an object ID or a regular object. In both cases, the arguments will be regular objects when the function executes. This means that even if you pass in an object ID, you do not need to call ray.get inside of these remote functions.
@ray.remotedefload_data(filename):time.sleep(0.1)returnnp.ones((1000,100))@ray.remotedefnormalize_data(data):time.sleep(0.1)returndata-np.mean(data,axis=0)@ray.remotedefextract_features(normalized_data):time.sleep(0.1)returnnp.hstack([normalized_data,normalized_data**2])@ray.remotedefcompute_loss(features):num_data,dim=features.shapetime.sleep(0.1)returnnp.sum((np.dot(features,np.ones(dim))-np.ones(num_data))**2)asserthasattr(load_data,'remote'),'load_data must be a remote function'asserthasattr(normalize_data,'remote'),'normalize_data must be a remote function'asserthasattr(extract_features,'remote'),'extract_features must be a remote function'asserthasattr(compute_loss,'remote'),'compute_loss must be a remote function'
EXERCISE: The loop below takes too long. Parallelize the four passes through the loop by turning load_data, normalize_data, extract_features, and compute_loss into remote functions and then retrieving the losses with ray.get.
NOTE: You should only use ONE call to ray.get. For example, the object ID returned by load_data should be passed directly into normalize_data without needing to be retrieved by the driver.
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(2.0)start_time=time.time()losses=[]forfilenamein['file1','file2','file3','file4']:inner_start=time.time()data=load_data.remote(filename)normalized_data=normalize_data.remote(data)features=extract_features.remote(normalized_data)loss=compute_loss.remote(features)losses.append(loss)inner_end=time.time()ifinner_end-inner_start>=0.1:raiseException('You may be calling ray.get inside of the for loop! ''Doing this will prevent parallelism from being exposed. ''Make sure to only call ray.get once outside of the for loop.')print('The losses are {}.'.format(losses)+'\n')loss=sum(ray.get(losses))end_time=time.time()duration=end_time-start_timeprint('The loss is {}. This took {} seconds. Run the next cell to see ''if the exercise was done correctly.'.format(loss,duration))# The losses are [ObjectID(c93d08295a9c442613ed4b4eca48f94ec6814f5b), ObjectID(b2826a902ef0845f30bc2ee0dd1ea4f78629bd8c), ObjectID(7dff67fd2906233ff53a5ea8d13932bb33f0031a), ObjectID(01d0071b7d8705f17673f5e660bd3d9c8a2c8ba1)].# The loss is 4000.0. This took 0.6542365550994873 seconds. Run the next cell to see if the exercise was done correctly.
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertloss==4000assertduration<0.8,('The loop took {} seconds. This is too slow.'.format(duration))assertduration>0.4,('The loop took {} seconds. This is too fast.'.format(duration))print('Success! The example took {} seconds.'.format(duration))# Success! The example took 0.6542365550994873 seconds.
EXERCISE: Use the UI to view the task timeline and to verify that the relevant tasks were executed in parallel. After running the cell below, you’ll need to click on View task timeline".
Using the second button, you can click and drag to move the timeline.
Using the third button, you can click and drag to zoom. You can also zoom by holding “alt” and scrolling.
In the timeline, click on View Options and select Flow Events to visualize tasks dependencies.
importray.experimental.uiasuiui.task_timeline()
Exercise 3 - Nested Parallelism
GOAL: The goal of this exercise is to show how to create nested tasks by calling a remote function inside of another remote function.
In this exercise, you will implement the structure of a parallel hyperparameter sweep which trains a number of models in parallel. Each model will be trained using parallel gradient computations.
Concepts for this Exercise - Nested Remote Functions
Remote functions can call other functions. For example, consider the following.
@ray.remotedeff():return1@ray.remotedefg():# Call f 4 times and return the resulting object IDs.return[f.remote()for_inrange(4)]@ray.remotedefh():# Call f 4 times, block until those 4 tasks finish,# retrieve the results, and return the values.returnray.get([f.remote()for_inrange(4)])
Then calling g and h produces the following behavior.
One limitation is that the definition of f must come before the definitions of g and h because as soon as g is defined, it will be pickled and shipped to the workers, and so if f hasn’t been defined yet, the definition will be incomplete.
This example represents a hyperparameter sweep in which multiple models are trained in parallel. Each model training task also performs data parallel gradient computations.
EXERCISE: Turn compute_gradient and train_model into remote functions so that they can be executed in parallel. Inside of train_model, do the calls to compute_gradient in parallel and fetch the results using ray.get.
@ray.remotedefcompute_gradient(data,current_model):time.sleep(0.03)return1@ray.remotedeftrain_model(hyperparameters):current_model=0# Iteratively improve the current model. This outer loop cannot be parallelized.for_inrange(10):# EXERCISE: Parallelize the list comprehension in the line below. After you# turn "compute_gradient" into a remote function, you will need to call it# with ".remote". The results must be retrieved with "ray.get" before "sum"# is called.total_gradient=sum(ray.get([compute_gradient.remote(j,current_model)forjinrange(2)]))current_model+=total_gradientreturncurrent_modelasserthasattr(compute_gradient,'remote'),'compute_gradient must be a remote function'asserthasattr(train_model,'remote'),'train_model must be a remote function'
EXERCISE: The code below runs 3 hyperparameter experiments. Change this to run the experiments in parallel.
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(2.0)start_time=time.time()# Run some hyperparaameter experiments.results=[]forhyperparametersin[{'learning_rate':1e-1,'batch_size':100},{'learning_rate':1e-2,'batch_size':100},{'learning_rate':1e-3,'batch_size':100}]:results.append(train_model.remote(hyperparameters))# EXERCISE: Once you've turned "results" into a list of Ray ObjectIDs# by calling train_model.remote, you will need to turn "results" back# into a list of integers, e.g., by doing "results = ray.get(results)".results=ray.get(results)end_time=time.time()duration=end_time-start_timeassertall([isinstance(x,int)forxinresults]),'Looks like "results" is {}. You may have forgotten to call ray.get.'.format(results)
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertresults==[20,20,20]assertduration<0.5,('The experiments ran in {} seconds. This is too ''slow.'.format(duration))assertduration>0.3,('The experiments ran in {} seconds. This is too ''fast.'.format(duration))print('Success! The example took {} seconds.'.format(duration))# Success! The example took 0.32144594192504883 seconds.
EXERCISE: Use the UI to view the task timeline and to verify that the pattern makes sense.
importray.experimental.uiasuiui.task_timeline()
Exercise 4 - Introducing Actors
Goal: The goal of this exercise is to show how to create an actor and how to call actor methods.
Sometimes you need a “worker” process to have “state”. For example, that state might be a neural network, a simulator environment, a counter, or something else entirely. However, remote functions are side-effect free. That is, they operate on inputs and produce outputs, but they don’t change the state of the worker they execute on.
Actors are different. When we instantiate an actor, a brand new worker is created, and all methods that are called on that actor are executed on the newly created worker.
This means that with a single actor, no parallelism can be achieved because calls to the actor’s methods will be executed one at a time. However, multiple actors can be created and methods can be executed on them in parallel.
Concepts for this Exercise - Actors
To create an actor, decorate Python class with the @ray.remote decorator.
Return Values: Actor methods are non-blocking. They immediately return an object ID and they create a task which is scheduled on the actor worker. The result can be retrieved with ray.get.
EXERCISE: Change the Foo class to be an actor class by using the @ray.remote decorator.
@ray.remoteclassFoo(object):def__init__(self):self.counter=0defreset(self):self.counter=0defincrement(self):time.sleep(0.5)self.counter+=1returnself.counterasserthasattr(Foo,'remote'),'You need to turn "Foo" into an actor with @ray.remote.'
EXERCISE: Change the intantiations below to create two actors by calling Foo.remote().
# Create two Foo objects.f1=Foo.remote()f2=Foo.remote()
EXERCISE: Parallelize the code below. The two actors can execute methods in parallel (though each actor can only execute one method at a time).
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(2.0)start_time=time.time()# Reset the actor state so that we can run this cell multiple times without# changing the results.f1.reset.remote()f2.reset.remote()# We want to parallelize this code. However, it is not straightforward to# make "increment" a remote function, because state is shared (the value of# "self.counter") between subsequent calls to "increment". In this case, it# makes sense to use actors.results=[]for_inrange(5):results.append(f1.increment.remote())results.append(f2.increment.remote())results=ray.get(results)end_time=time.time()duration=end_time-start_timeassertnotany([isinstance(result,ray.ObjectID)forresultinresults]),'Looks like "results" is {}. You may have forgotten to call ray.get.'.format(results)
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertresults==[1,1,2,2,3,3,4,4,5,5]assertduration<3,('The experiments ran in {} seconds. This is too ''slow.'.format(duration))assertduration>2.5,('The experiments ran in {} seconds. This is too ''fast.'.format(duration))print('Success! The example took {} seconds.'.format(duration))# Success! The example took 2.5102529525756836 seconds.
Exercise 5 - Actor Handles
GOAL: The goal of this exercise is to show how to pass around actor handles.
Suppose we wish to have multiple tasks invoke methods on the same actor. For example, we may have a single actor that records logging information from a number of tasks. We can achieve this by passing a handle to the actor as an argument into the relevant tasks.
Concepts for this Exercise - Actor Handles
First of all, suppose we’ve created an actor as follows.
@ray.remoteclassActor(object):defmethod(self):pass# Create the actoractor=Actor.remote()
Then we can define a remote function (or another actor) that takes an actor handle as an argument.
@ray.remotedeff(actor):# We can invoke methods on the actor.x_id=actor.method.remote()# We can block and get the results.returnray.get(x_id)
Then we can invoke the remote function a few times and pass in the actor handle.
# Each of the three tasks created below will invoke methods on the same actor.f.remote(actor)f.remote(actor)f.remote(actor)
In this exercise, we’re going to write some code that runs several “experiments” in parallel and has each experiment log its results to an actor. The driver script can then periodically pull the results from the logging actor.
EXERCISE: Turn this LoggingActor class into an actor class.
@ray.remoteclassLoggingActor(object):def__init__(self):self.logs=defaultdict(lambda:[])deflog(self,index,message):self.logs[index].append(message)defget_logs(self):returndict(self.logs)asserthasattr(LoggingActor,'remote'),('You need to turn LoggingActor into an ''actor (by using the ray.remote keyword).')
EXERCISE: Instantiate the actor.
logging_actor=LoggingActor.remote()# Some checks to make sure this was done correctly.asserthasattr(logging_actor,'get_logs')
Now we define a remote function that runs and pushes its logs to the LoggingActor.
EXERCISE: Modify this function so that it invokes methods correctly on logging_actor (you need to change the way you call the log method).
@ray.remotedefrun_experiment(experiment_index,logging_actor):foriinrange(60):time.sleep(1)# Push a logging message to the actor.logging_actor.log.remote(experiment_index,'On iteration {}'.format(i))
Now we create several tasks that use the logging actor.
While the experiments are running in the background, the driver process (that is, this Jupyter notebook) can query the actor to read the logs.
EXERCISE: Modify the code below to dispatch methods to the LoggingActor.
logs=ray.get(logging_actor.get_logs.remote())print(logs)assertisinstance(logs,dict),("Make sure that you dispatch tasks to the ""actor using the .remote keyword and get the results using ray.get.")#{0: ['On iteration 0'], # 1: ['On iteration 0'], # 2: ['On iteration 0']}
EXERCISE: Try running the above box multiple times and see how the results change (while the experiments are still running in the background). You can also try running more of the experiment tasks and see what happens.
This script starts 6 tasks, each of which takes a random amount of time to complete. We’d like to process the results in two batches (each of size 3). Change the code so that instead of waiting for a fixed set of 3 tasks to finish, we make the first batch consist of the first 3 tasks that complete. The second batch should consist of the 3 remaining tasks. Do this exercise by using ray.wait.
Concepts for this Exercise - ray.wait
After launching a number of tasks, you may want to know which ones have finished executing. This can be done with ray.wait. The function works as follows.
num_returns: This is maximum number of object IDs to wait for. The default value is 1.
timeout: This is the maximum amount of time in milliseconds to wait for. So ray.wait will block until either num_returns objects are ready or until timeout milliseconds have passed.
Return values:
ready_ids: This is a list of object IDs that are available in the object store.
remaining_ids: This is a list of the IDs that were in object_ids but are not in ready_ids, so the IDs in ready_ids and remaining_ids together make up all the IDs in object_ids.
EXERCISE: Using ray.wait, change the code below so that initial_results consists of the outputs of the first three tasks to complete instead of the first three tasks that were submitted.
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(2.0)start_time=time.time()# This launches 6 tasks, each of which takes a random amount of time to# complete.result_ids=ray.wait([f.remote(i)foriinrange(6)],num_returns=3,timeout=None)# Get one batch of tasks. Instead of waiting for a fixed subset of tasks, we# should instead use the first 3 tasks that finish.# initial_results = ray.get(result_ids[:3])initial_results=ray.get(result_ids[0])end_time=time.time()duration=end_time-start_time
EXERCISE: Change the code below so that remaining_results consists of the outputs of the last three tasks to complete.
# Wait for the remaining tasks to complete.# remaining_results = ray.get(result_ids[3:])remaining_results=ray.get(result_ids[1])
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertlen(initial_results)==3assertlen(remaining_results)==3initial_indices=[result[0]forresultininitial_results]initial_times=[result[1]forresultininitial_results]remaining_indices=[result[0]forresultinremaining_results]remaining_times=[result[1]forresultinremaining_results]assertset(initial_indices+remaining_indices)==set(range(6))assertduration<1.5,('The initial batch of ten tasks was retrieved in ''{} seconds. This is too slow.'.format(duration))assertduration>0.8,('The initial batch of ten tasks was retrieved in ''{} seconds. This is too slow.'.format(duration))# Make sure the initial results actually completed first.assertmax(initial_times)<min(remaining_times)print('Success! The example took {} seconds.'.format(duration))# Success! The example took 0.893179178237915 seconds.
Exercise 7 - Process Tasks in Order of Completion
GOAL: The goal of this exercise is to show how to use ray.wait to process tasks in the order that they finish.
The code below runs 10 tasks and retrieves the results in the order that the tasks were launched. However, since each task takes a random amount of time to finish, we could instead process the tasks in the order that they finish.
EXERCISE: Change the code below to use ray.wait to get the results of the tasks in the order that they complete.
NOTE: It would be a simple modification to maintain a pool of 10 experiments and to start a new experiment whenever one finishes.
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(2.0)start_time=time.time()# result_ids = [f.remote() for _ in range(10)]temp=ray.wait([f.remote()for_inrange(10)],num_returns=1,timeout=None)result_ids=temp[0]whiletemp[1]:temp=ray.wait(temp[1],num_returns=1,timeout=None)result_ids.extend(temp[0])# Get the results.results=[]forresult_idinresult_ids:result=ray.get(result_id)results.append(result)print('Processing result which finished after {} seconds.'.format(result-start_time))end_time=time.time()duration=end_time-start_time# Processing result which finished after 1.5440089702606201 seconds.# Processing result which finished after 1.8363125324249268 seconds.# Processing result which finished after 2.719313144683838 seconds.# Processing result which finished after 3.2043678760528564 seconds.# Processing result which finished after 3.8053157329559326 seconds.# Processing result which finished after 3.9189162254333496 seconds.# Processing result which finished after 4.422319412231445 seconds.# Processing result which finished after 5.62132453918457 seconds.# Processing result which finished after 6.22131085395813 seconds.# Processing result which finished after 6.867010593414307 seconds.
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertresults==sorted(results),('The results were not processed in the ''order that they finished.')print('Success! The example took {} seconds.'.format(duration))# Success! The example took 6.874698162078857 seconds.
Exercise 8 - Speed up Serialization
GOAL: The goal of this exercise is to illustrate how to speed up serialization by using ray.put.
Concepts for this Exercise - ray.put
Object IDs can be created in multiple ways.
They are returned by remote function calls.
They are returned by actor method calls.
They are returned by ray.put.
When an object is passed to ray.put, the object is serialized using the Apache Arrow format (see https://arrow.apache.org/ for more information about Arrow) and copied into a shared memory object store. This object will then be available to other workers on the same machine via shared memory. If it is needed by workers on another machine, it will be shipped under the hood.
When objects are passed into a remote function, Ray puts them in the object store under the hood. That is, if f is a remote function, the code
x=np.zeros(1000)f.remote(x)
is essentially transformed under the hood to
x=np.zeros(1000)x_id=ray.put(x)f.remote(x_id)
The call to ray.put copies the numpy array into the shared-memory object store, from where it can be read by all of the worker processes (without additional copying). However, if you do something like
foriinrange(10):f.remote(x)
then 10 copies of the array will be placed into the object store. This takes up more memory in the object store than is necessary, and it also takes time to copy the array into the object store over and over. This can be made more efficient by placing the array in the object store only once as follows.
x_id=ray.put(x)foriinrange(10):f.remote(x_id)
In this exercise, you will speed up the code below and reduce the memory footprint by calling ray.put on the neural net weights before passing them into the remote functions.
WARNING: This exercise requires a lot of memory to run. If this notebook is running within a Docker container, then the docker container must be started with a large shared-memory file system. This can be done by starting the docker container with the --shm-size flag.
Define some neural net weights which will be passed into a number of tasks.
# neural_net_weights = {'variable{}'.format(i): np.random.normal(size=1000000)# for i in range(50)} # 这个好像有误neural_net_weights=np.random.normal(size=1000000)
EXERCISE: Compare the time required to serialize the neural net weights and copy them into the object store using Ray versus the time required to pickle and unpickle the weights. The big win should be with the time required for deserialization.
Note that when you call ray.put, in addition to serializing the object, we are copying it into shared memory where it can be efficiently accessed by other workers on the same machine.
NOTE: You don’t actually have to do anything here other than run the cell below and read the output.
NOTE: Sometimes ray.put can be faster than pickle.dumps. This is because ray.put leverages multiple threads when serializing large objects. Note that this is not possible with pickle.
print('Ray - serializing')%timex_id=ray.put(neural_net_weights)print('\nRay - deserializing')%timex_val=ray.get(x_id)print('\npickle - serializing')%timeserialized=pickle.dumps(neural_net_weights)print('\npickle - deserializing')%timedeserialized=pickle.loads(serialized)# Ray - serializing# CPU times: user 35.9 ms, sys: 47.9 ms, total: 83.7 ms# Wall time: 61.6 ms# Ray - deserializing# CPU times: user 1.07 ms, sys: 0 ns, total: 1.07 ms# Wall time: 1.04 ms# pickle - serializing# CPU times: user 85.8 ms, sys: 103 ms, total: 189 ms# Wall time: 193 ms# pickle - deserializing# CPU times: user 2.25 ms, sys: 0 ns, total: 2.25 ms# Wall time: 2.28 ms
Define a remote function which uses the neural net weights.
@ray.remotedefuse_weights(weights,i):returni
EXERCISE: In the code below, use ray.put to avoid copying the neural net weights to the object store multiple times.
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(2.0)start_time=time.time()temp=ray.put(neural_net_weights)results=ray.get([use_weights.remote(temp,i)foriinrange(20)])end_time=time.time()duration=end_time-start_time
VERIFY: Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertresults==list(range(20))assertduration<1,('The experiments ran in {} seconds. This is too ''slow.'.format(duration))print('Success! The example took {} seconds.'.format(duration))# Success! The example took 0.10664176940917969 seconds.
Exercise 9 - Using the GPU API
GOAL: The goal of this exercise is to show how to use GPUs with remote functions and actors.
NOTE: These exercises are designed to run on a machine without GPUs.
We can indicate that a remote function or an actor requires some GPUs using the num_gpus keyword.
@ray.remote(num_gpus=1)deff():# The command ray.get_gpu_ids() returns a list of the indices# of the GPUs that this task can use (e.g., [0] or [1]).ray.get_gpu_ids()@ray.remote(num_gpus=2)classFoo(object):def__init__(self):# The command ray.get_gpu_ids() returns a list of the# indices of the GPUs that this actor can use# (e.g., [0, 1] or [3, 5]).ray.get_gpu_ids()
Then inside of the actor constructor and methods, we can get the IDs of the GPUs allocated for that actor with ray.get_gpu_ids().
Start Ray, note that we pass in num_gpus=4. Ray will assume this machine has 4 GPUs (even if it does not). When a task or actor requests a GPU, it will be assigned a GPU ID from the set [0, 1, 2, 3]. It is then the responsibility of the task or actor to make sure that it only uses that specific GPU (e.g., by setting the CUDA_VISIBLE_DEVICES environment variable).
EXERCISE: Change the remote function below to require one GPU.
NOTE: This change does not make the remote function actually use the GPU, it simply reserves the GPU for use by the remote function. To actually use the GPU, the remote function would use a neural net library like TensorFlow or PyTorch after setting the CUDA_VISIBLE_DEVICES environment variable properly. This can be done as follows.
VERIFY: This code checks that each task was assigned one GPU and that not more than two tasks are run at the same time (because we told Ray there are only two GPUs).
start_time=time.time()gpu_ids=ray.get([f.remote()for_inrange(3)])# [[1], [0], [0]]end_time=time.time()foriinrange(len(gpu_ids)):assertlen(gpu_ids[i])==1assertend_time-start_time>1print('Sucess! The test passed.')# Sucess! The test passed.
EXERCISE: The code below defines an actor. Make it require one GPU.
Concepts for this Exercise - Using Custom Resources
We’ve discussed how to specify a task’s CPU and GPU requirements, but there are many other kinds of resources. For example, a task may require a dataset, which only lives on a few machines, or it may need to be scheduled on a machine with extra memory. These kinds of requirements can be expressed through the use of custom resources.
Custom resources are most useful in the multi-machine setting. However, this exercise illustrates their usage in the single-machine setting.
Ray can be started with a dictionary of custom resources (mapping resource name to resource quantity) as follows.
Even if there are many CPUs on the machine, only 4 copies of f can be executed concurrently.
Custom resources give applications a great deal of flexibility. For example, if you wish to control precisely which machine a task gets scheduled on, you can simply start each machine with a different custom resource (e.g., start machine n with resource Custom_n and then tasks that should be scheduled on machine n can require resource Custom_n. However, this usage has drawbacks because it makes the code less portable and less resilient to machine failures.
If you did the above exercise correctly, the next cell should execute without raising an exception.
start=time.time()ray.get([f.remote()for_inrange(8)])duration=time.time()-startassertduration>=0.1andduration<0.19,'8 f tasks should be able to execute concurrently.'start=time.time()ray.get([f.remote()for_inrange(9)])duration=time.time()-startassertduration>=0.2andduration<0.29,'f tasks should not be able to execute concurrently.'start=time.time()ray.get([g.remote()for_inrange(4)])duration=time.time()-startassertduration>=0.1andduration<0.19,'4 g tasks should be able to execute concurrently.'start=time.time()ray.get([g.remote()for_inrange(5)])duration=time.time()-startassertduration>=0.2andduration<0.29,'5 g tasks should not be able to execute concurrently.'start=time.time()ray.get([f.remote()for_inrange(4)]+[g.remote()for_inrange(4)])duration=time.time()-startassertduration>=0.1andduration<0.19,'4 f and 4 g tasks should be able to execute concurrently.'start=time.time()ray.get([f.remote()for_inrange(5)]+[g.remote()for_inrange(4)])duration=time.time()-startassertduration>=0.2andduration<0.29,'5 f and 4 g tasks should not be able to execute concurrently.'print('Success!')# Success!
Exercise 11 - Pass Neural Net Weights Between Processes
GOAL: The goal of this exercise is to show how to send neural network weights between workers and the driver.
Concepts for this Exercise - Getting and Setting Neural Net Weights
Since pickling and unpickling a TensorFlow graph can be inefficient or may not work at all, it is most efficient to ship the weights between processes as a dictionary of numpy arrays (or as a flattened numpy array).
We provide the helper class ray.experimental.TensorFlowVariables to help with getting and setting weights. Similar techniques should work other neural net libraries.
variables=ray.experimental.TensorFlowVariables(loss,sess)# Here 'weights' is a dictionary mapping variable names to the associated# weights as a numpy array.weights=variables.get_weights()variables.set_weights(weights)
Note that there are analogous methods variables.get_flat and variables.set_flat, which concatenate the weights as a single array instead of a dictionary.
# Here 'weights' is a numpy array of all of the neural net weights# concatenated together.weights=variables.get_flat()variables.set_flat(weights)
In this exercise, we will use an actor containing a neural network and implement methods to extract and set the neural net weights.
WARNING: This exercise is more complex than previous exercises.
The code below defines a class containing a simple neural network.
EXERCISE: Implement the set_weights and get_weights methods. This should be done using the ray.experimental.TensorFlowVariables helper class.
@ray.remoteclassSimpleModel(object):def__init__(self):x_data=tf.placeholder(tf.float32,shape=[100])y_data=tf.placeholder(tf.float32,shape=[100])w=tf.Variable(tf.random_uniform([1],-1.0,1.0))b=tf.Variable(tf.zeros([1]))y=w*x_data+bself.loss=tf.reduce_mean(tf.square(y-y_data))optimizer=tf.train.GradientDescentOptimizer(0.5)grads=optimizer.compute_gradients(self.loss)self.train=optimizer.apply_gradients(grads)init=tf.global_variables_initializer()self.sess=tf.Session()# Here we create the TensorFlowVariables object to assist with getting# and setting weights.self.variables=ray.experimental.TensorFlowVariables(self.loss,self.sess)self.sess.run(init)defset_weights(self,weights):"""Set the neural net weights.
This method should assign the given weights to the neural net.
Args:
weights: Either a dict mapping strings (the variable names) to numpy
arrays or a single flattened numpy array containing all of the
concatenated weights.
"""# EXERCISE: You will want to use self.variables here.self.variables.set_weights(weights)# raise NotImplementedErrordefget_weights(self):"""Get the neural net weights.
This method should return the current neural net weights.
Returns:
Either a dict mapping strings (the variable names) to numpy arrays or
a single flattened numpy array containing all of the concatenated
weights.
"""# EXERCISE: You will want to use self.variables here.returnself.variables.get_weights()# raise NotImplementedError
Create a few actors.
actors=[SimpleModel.remote()for_inrange(4)]
EXERCISE: Get the neural net weights from all of the actors.
NOTE: This will be easier to do if you chose to use get_flat/set_flat instead of get_weights/set_weights in the implementation of SimpleModel.set_weights and SimpleModel.get_weights above..
VERIFY: Check that all of the actors have the same weights.
weights=ray.get([actor.get_weights.remote()foractorinactors])foriinrange(len(weights)):np.testing.assert_equal(weights[i],weights[0])print('Success! The test passed.')# Success! The test passed.
Exercise 12 - Tree Reduce
GOAL: The goal of this exercise is to show how to implement a tree reduce in Ray by passing object IDs into remote functions to encode dependencies between tasks.
In this exercise, you will use Ray to implement parallel data generation and a parallel tree reduction.
EXERCISE: These functions will need to be turned into remote functions so that the tree of tasks can be executed in parallel.
# This is a proxy for a function which generates some data.@ray.remotedefcreate_data(i):time.sleep(0.3)returni*np.ones(10000)# This is a proxy for an expensive aggregation step (which is also# commutative and associative so it can be used in a tree-reduce).@ray.remotedefaggregate_data(x,y):time.sleep(0.3)returnx*y
EXERCISE: Make the data creation tasks run in parallel. Also aggregate the vectors in parallel. Note that the aggregate_data function must be called 7 times. They cannot all run in parallel because some depend on the outputs of others. However, it is possible to first run 4 in parallel, then 2 in parallel, and then 1.
# Sleep a little to improve the accuracy of the timing measurements below.time.sleep(1.0)start_time=time.time()# EXERCISE: Here we generate some data. Do this part in parallel.vectors=[create_data.remote(i+1)foriinrange(8)]# Here we aggregate all of the data repeatedly calling aggregate_data. This# can be sped up using Ray.## NOTE: A direct translation of the code below to use Ray will not result in# a speedup because each function call uses the output of the previous function# call so the function calls must be executed serially.## EXERCISE: Speed up the aggregation below by using Ray. Note that this will# require restructuring the code to expose more parallelism. First run 4 tasks# aggregating the 8 values in pairs. Then run 2 tasks aggregating the resulting# 4 intermediate values in pairs. then run 1 task aggregating the two resulting# values. Lastly, you will need to call ray.get to retrieve the final result.## Exposing more parallelism means aggregating the vectors in a DIFFERENT ORDER.# This can be done because we are simply summing the data and the order in# which the values are summed doesn't matter (it's commutative and associative).# result = aggregate_data(vectors[0], vectors[1])# result = aggregate_data(result, vectors[2])# result = aggregate_data(result, vectors[3])# result = aggregate_data(result, vectors[4])# result = aggregate_data(result, vectors[5])# result = aggregate_data(result, vectors[6])# result = aggregate_data(result, vectors[7])whilelen(vectors)>1:vectors.append(aggregate_data.remote(vectors.pop(0),vectors.pop(0)))# + vectors[2:]result=ray.get(vectors[0])# NOTE: For clarity, the aggregation above is written out as 7 separate function# calls, but this can be done more easily in a while loop via## while len(vectors) > 1:# vectors = aggregate_data(vectors[0], vectors[1]) + vectors[2:]# result = vectors[0]## When expressed this way, the change from serial aggregation to tree-structured# aggregation can be made simply by appending the result of aggregate_data to the# end of the vectors list as opposed to the beginning.## EXERCISE: Think about why this is true.end_time=time.time()duration=end_time-start_time
EXERCISE: Use the UI to view the task timeline and to verify that the vectors were aggregated with a tree of tasks.
You should be able to see the 8 create_data tasks running in parallel followed by 4 aggregate_data tasks running in parallel followed by 2 more aggregate_data tasks followed by 1 more aggregate_data task.
In the timeline, click on View Options and select Flow Events to visualize tasks dependencies.
importray.experimental.uiasuiui.task_timeline()
VERIFY:** Run some checks to verify that the changes you made to the code were correct. Some of the checks should fail when you initially run the cells. After completing the exercises, the checks should pass.
assertnp.all(result==40320*np.ones(10000)),('Did you remember to ''call ray.get?')assertduration<0.3+0.9+0.3,('FAILURE: The data generation and ''aggregation took {} seconds. This is ''too slow'.format(duration))assertduration>0.3+0.9,('FAILURE: The data generation and ''aggregation took {} seconds. This is ''too fast'.format(duration))print('Success! The example took {} seconds.'.format(duration))# Success! The example took 1.2151989936828613 seconds.